|
I am an incoming PhD student at UC Berkeley, currently a research intern at the Vision & Learning Lab. My research focuses on spoken language models and spoken dialogue systems. Email / CV / Google Scholar / Semantic Scholar / Twitter / Github / Linkedin |

|
|
* indicates equally contributed. Some of my notable papers are highlighted. |
|
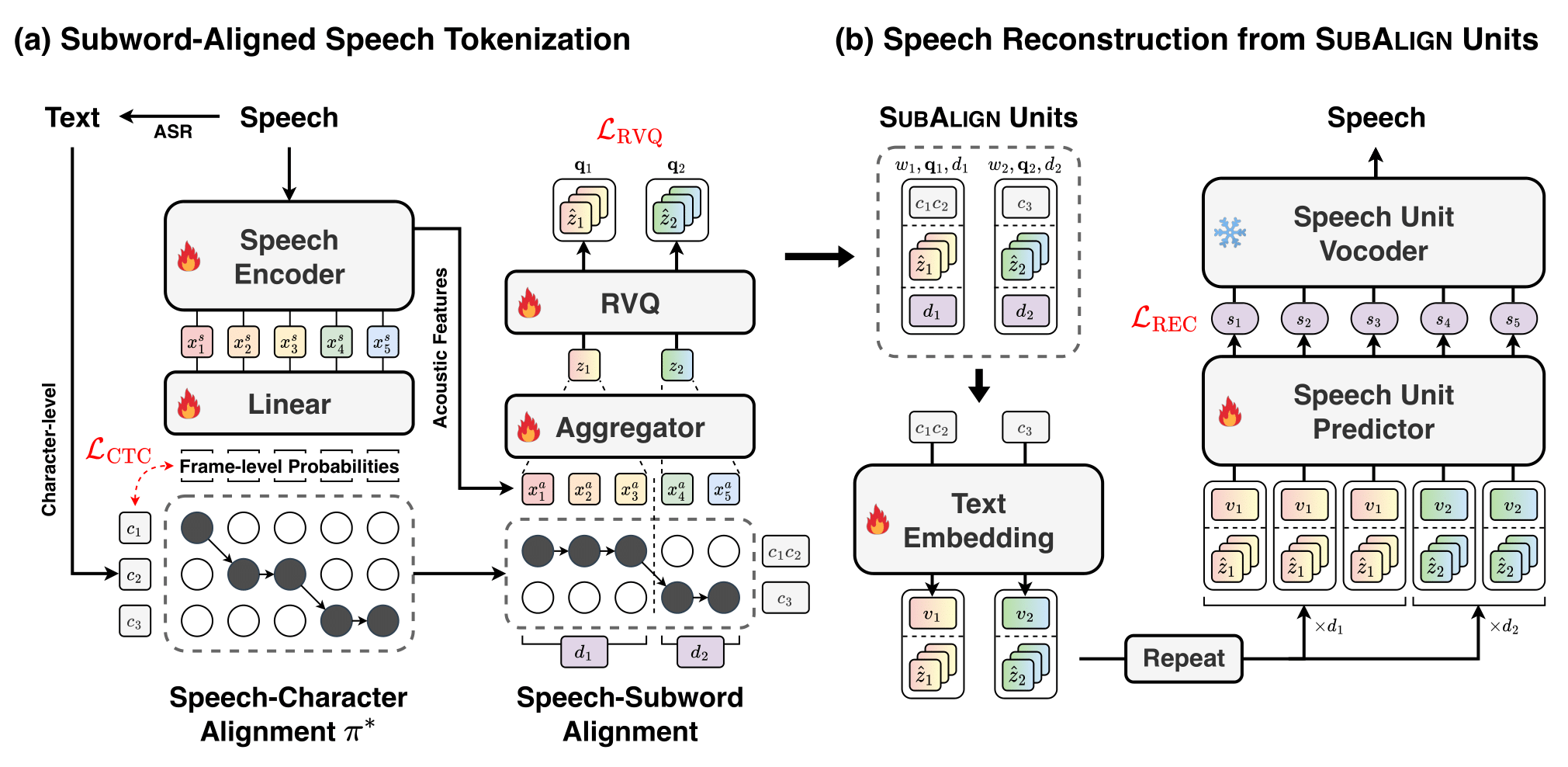
Kang-wook Kim, Sehun Lee, Sang Hoon Woo, Gunhee Kim TTIC Summer Workshop on Foundations of Speech and Audio Foundation Models 2025 (Oral) We present SubAlign, the first speech tokenization framework to explicitly segment speech at the subword level corresponding to LLM vocabularies. |
|
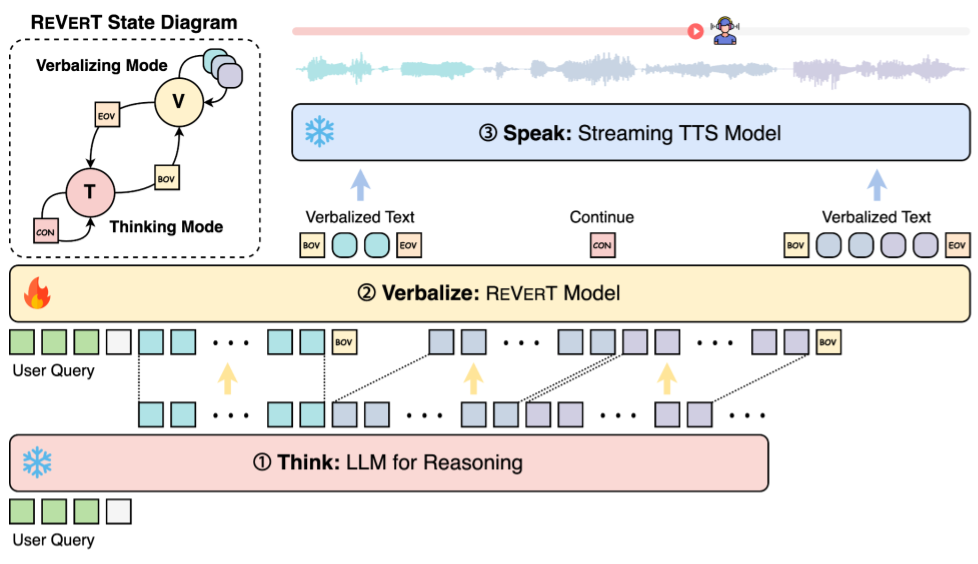
Sang Hoon Woo*, Sehun Lee*, Kang-wook Kim, Gunhee Kim EMNLP 2025 pdf / project page We introduce an explicit "verbalization" step that translates model thoughts into speech-friendly utterances for spoken dialogue systems, along with ReVerT, an efficient verbalization model. |
|
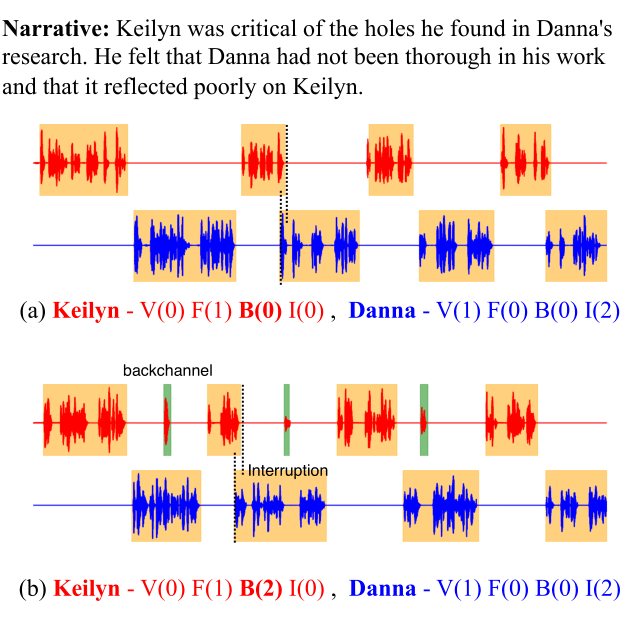
Sehun Lee*, Kang-wook Kim*, Gunhee Kim NAACL 2025 (Oral) 🏆 Senior Area Chair Award (Top 0.3%) 🏆 – Top Paper in Speech Processing and Spoken Language Understanding pdf / project page We present Behavior-SD and BeDLM, enabling large language models to generate natural, full-duplex spoken dialogues enriched with human conversational behaviors. |
|
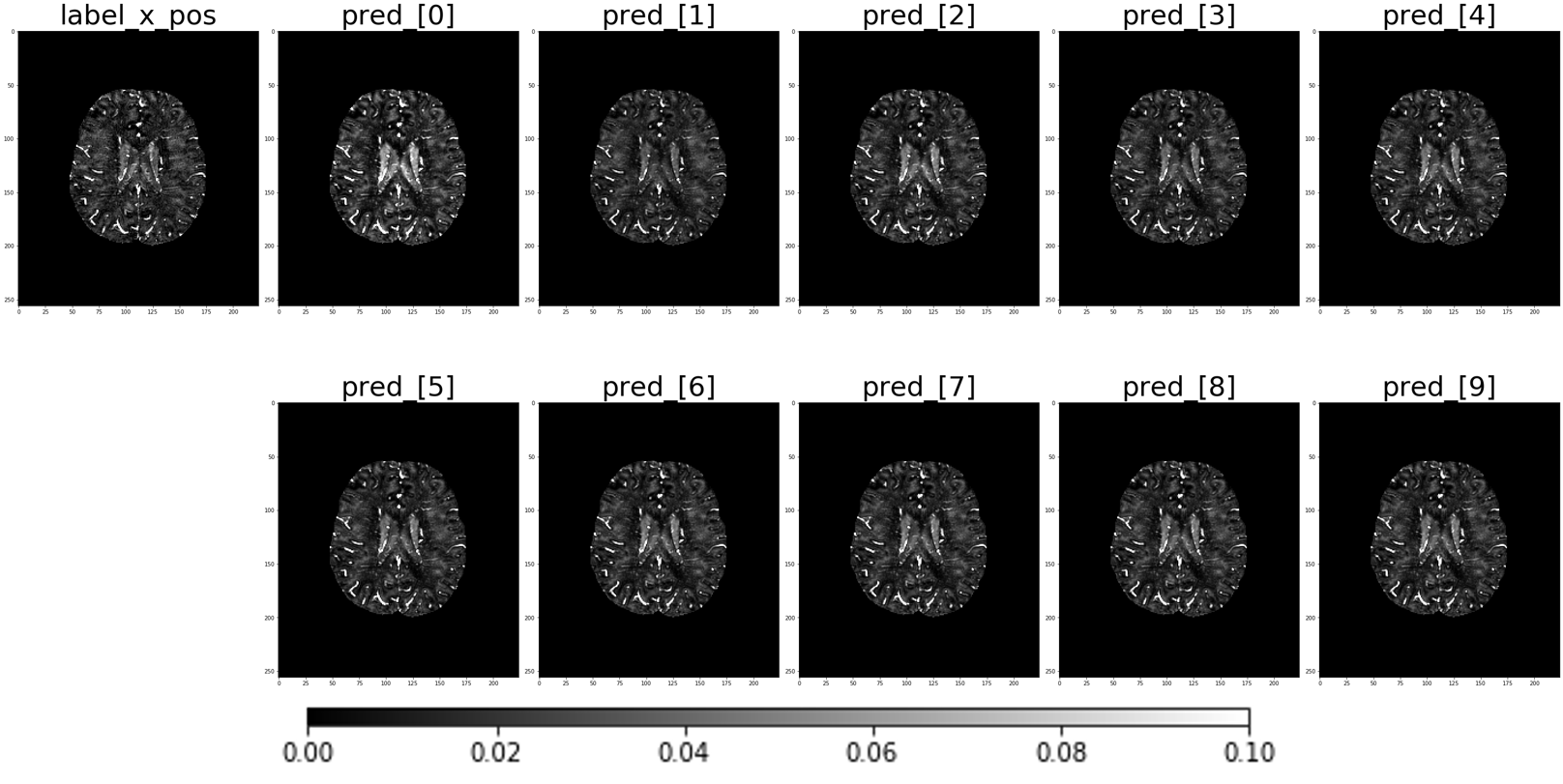
Kang-wook Kim Undergraduate Thesis pdf / poster I enhanced χ-sepnet with physics-informed unrolling to improve MRI susceptibility mapping accuracy but withheld ISMRM 2024 submission due to the model's underestimation of susceptibility in patient data, requiring further refinement. |

|
Ki-Ung Song*, Dongseok Shim*, Kang-wook Kim*, Jae-young Lee, Younggeun Kim CVPR 2022 NTIRE Workshop 2nd place on the NTIRE Learning Super-Resolution Space Challenge 4X track and 1st place on the 8X track. |
|
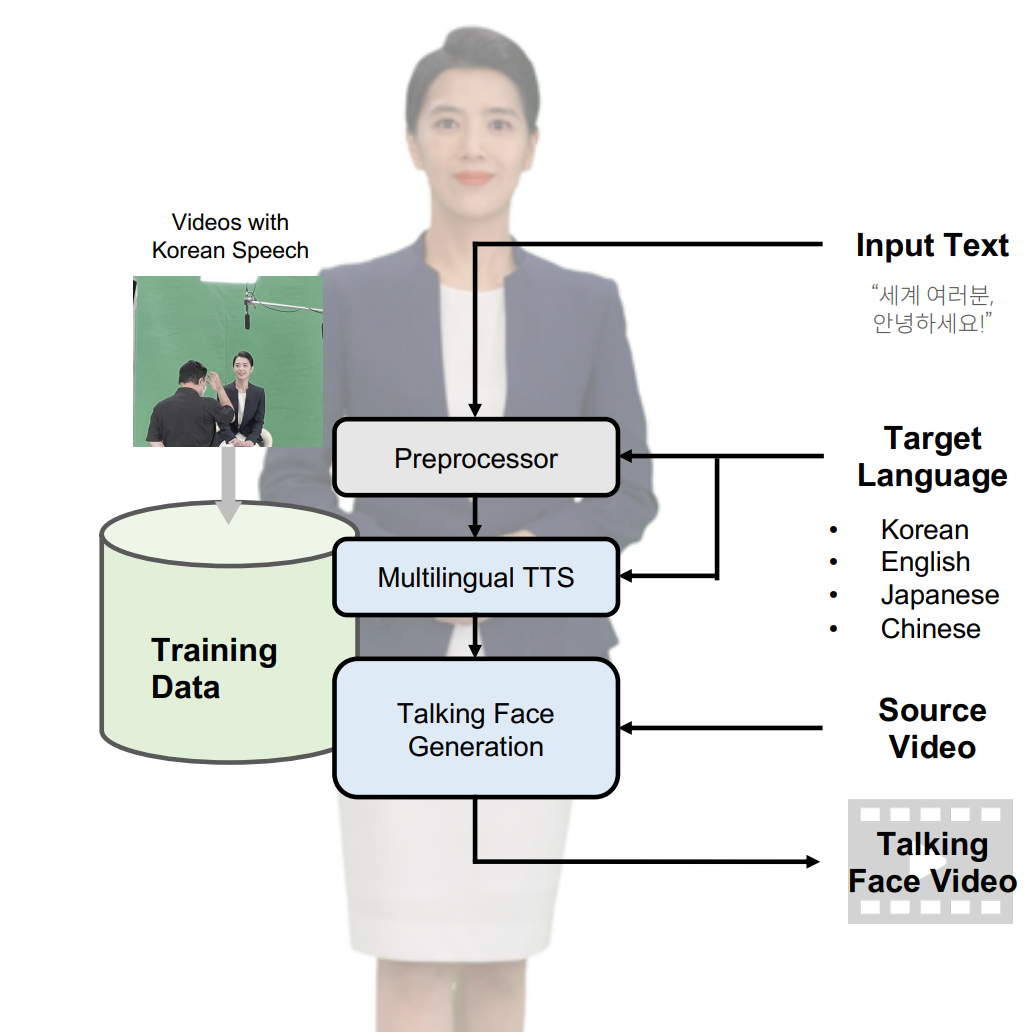
Hyoung-Kyu Song*, Sang Hoon Woo*, Junhyeok Lee, Seungmin Yang, Hyunjae Cho, Youseong Lee, Dongho Choi, Kang-wook Kim CVPR Demo Track, 2022 pdf / Demo Our team developed a multilingual system that generates lip-synced talking face videos from text in four languages while preserving speaker identity. |
|
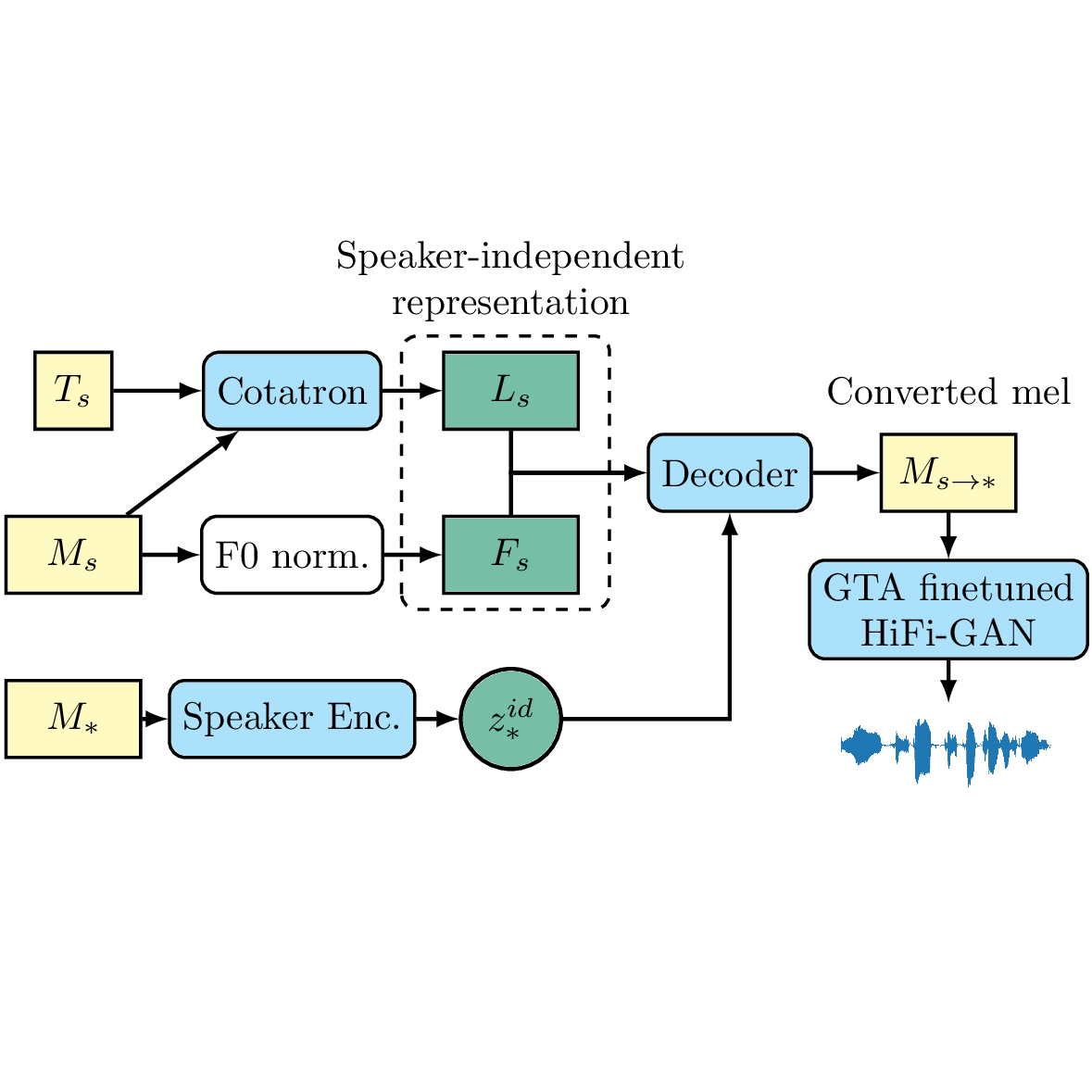
Kang-wook Kim, Seung-won Park, Junhyeok Lee, Myun-chul Joe Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022 pdf / project page / github We propose Assem-VC, a voice conversion system that combines modern techniques for realistic any-to-many conversion while preserving rhythm and intonation. |
|
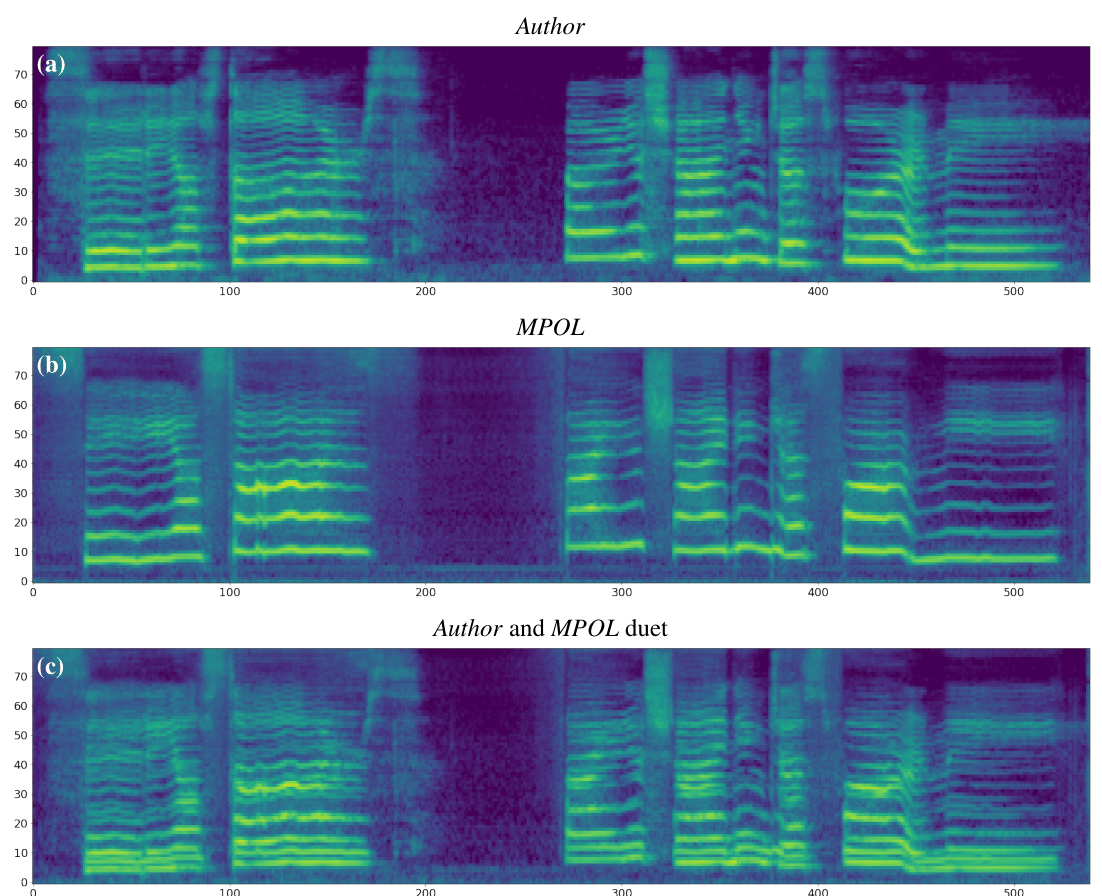
Kang-wook Kim, Junhyeok Lee NeurIPS Workshop on ML for Creativity and Design, 2021 (Oral, top 6.2%) pdf / project page / github / bibtex We propose a controllable singing decomposition system that encodes time-aligned linguistic content, pitch, and source speaker identity via Assem-VC. |